
How to Create Virtual Talking Avatars
This guide gives a practical end-to-end workflow for building virtual talking avatar videos, similar to modern creator tutorials and demos.
Updated: February 22, 2026.
This guide gives a practical end-to-end workflow for building virtual talking avatar videos, similar to modern creator tutorials and demos.
Updated: February 22, 2026.
A short, spoken script split into scenes (hook, body, CTA).
How to do it:
Quality checks:
Natural narration voice (stock or cloned) aligned with brand tone.
How to do it:
Quality checks:
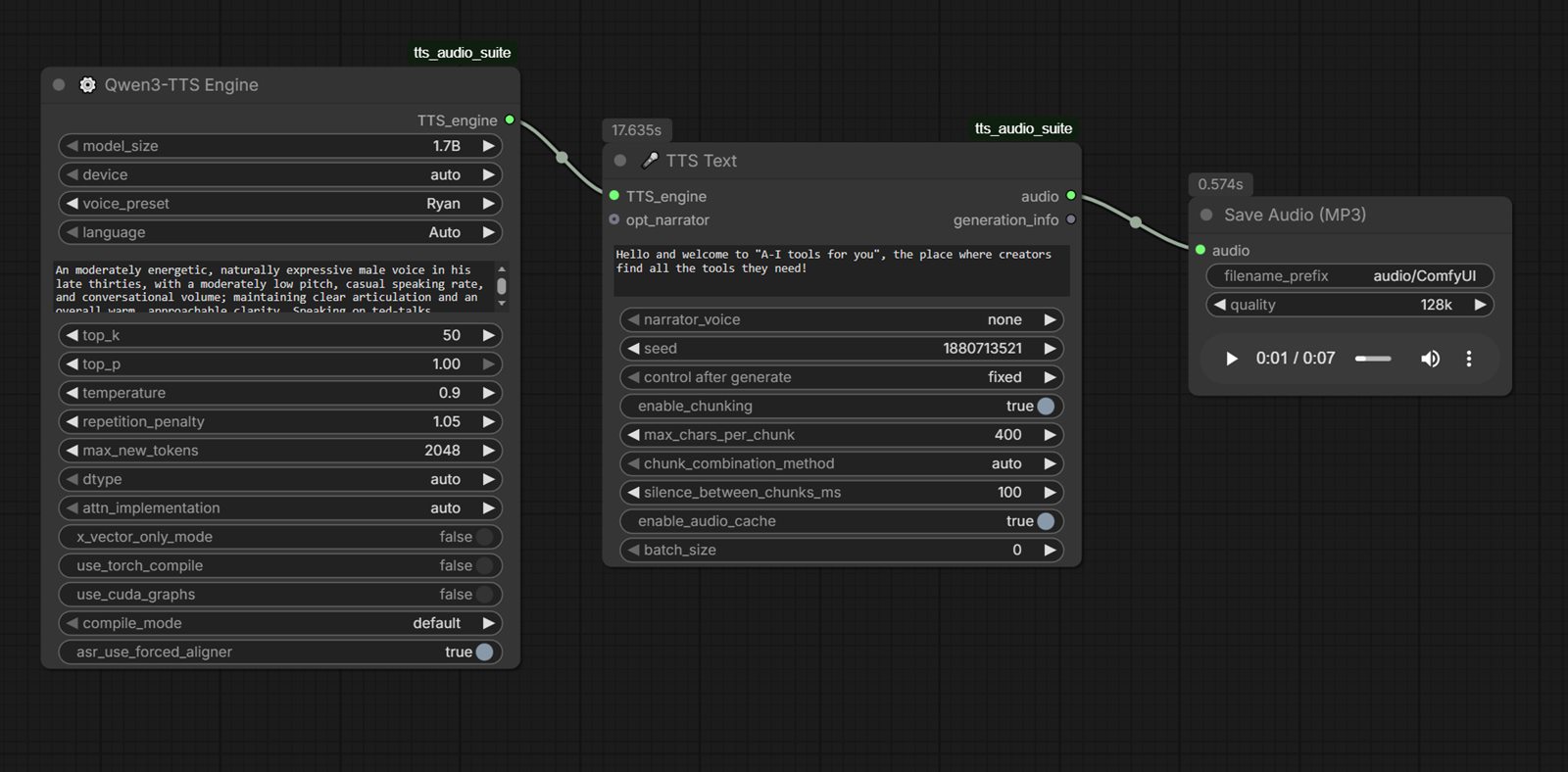
Sample output audio (Qwen3 TTS):
Direct file: comfyui-qwen3-tts-sample.mp3
Tools: ElevenLabs , Murf , Piper TTS (local) , ComfyUI TTS (local)
A clean portrait/character image to drive talking animation.
How to do it:
Quality checks:
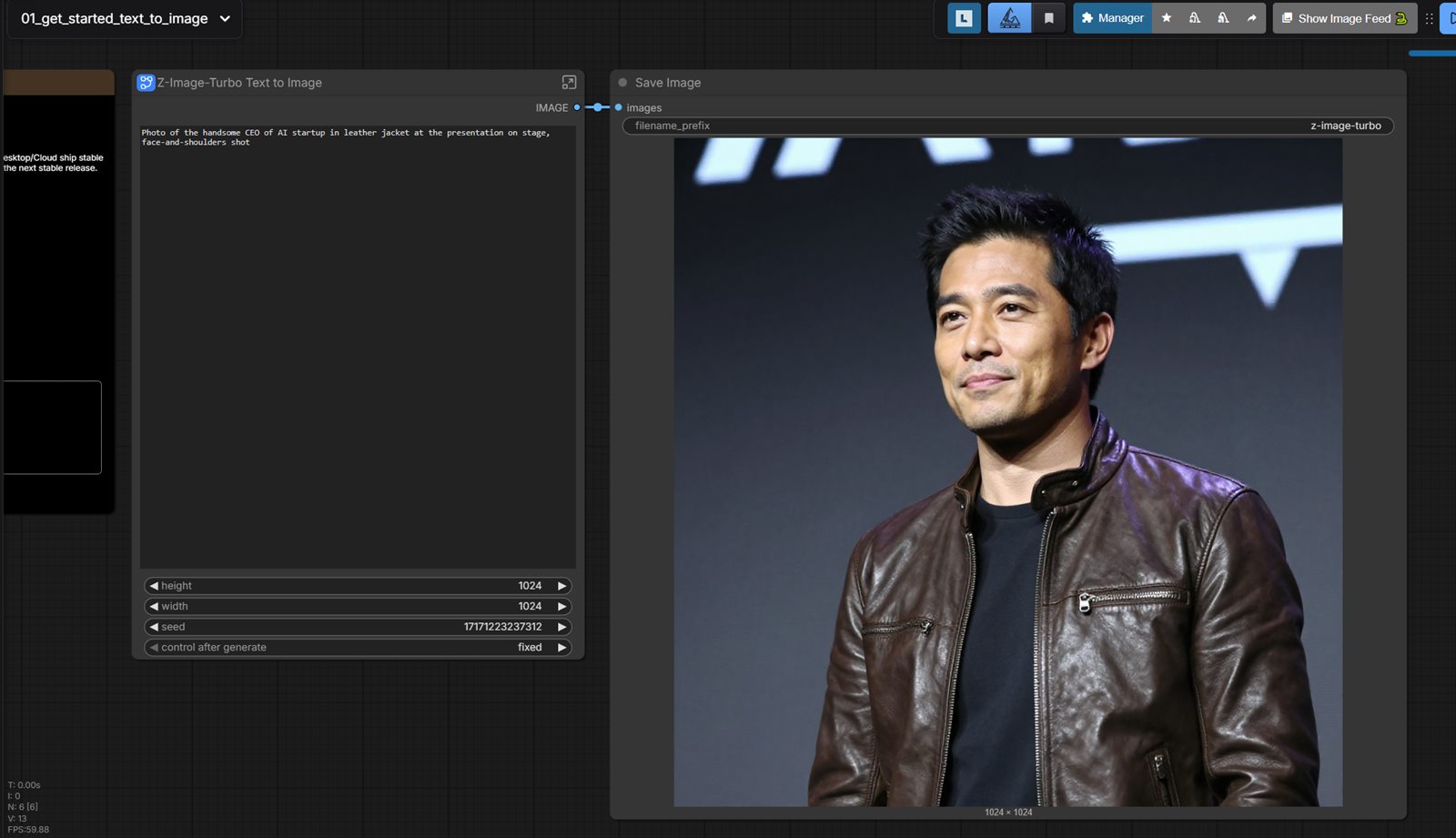
Tools: Midjourney , Leonardo AI , Adobe Firefly , ComfyUI (local)
Lip-synced avatar speaking your script/audio.
How to do it:
Quality checks:
Offline or self-hosted talking portrait workflow.
How to do it:
Quality checks:
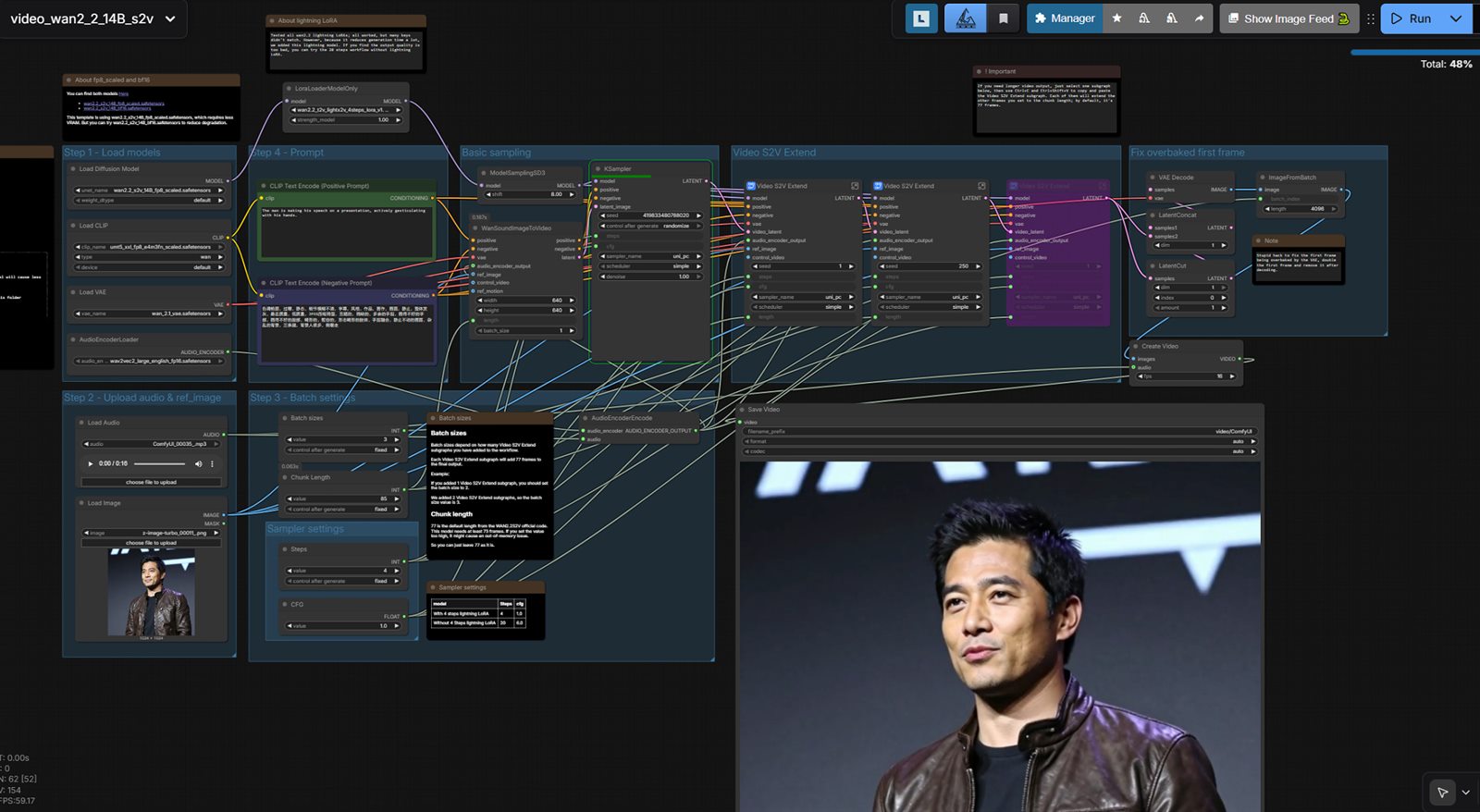
Tools: LivePortrait , SadTalker , ComfyUI
Platform-ready video with subtitles and pacing tuned for retention.
How to do it:
Quality checks:
| Stage | Cloud Tools | Local/Free Tools | Practical Note |
|---|---|---|---|
| Script | ChatGPT , Claude | Ollama , local models | Keep script short and spoken-language friendly. |
| Voice | ElevenLabs , Murf | Piper TTS , Coqui TTS , Kokoro TTS , ComfyUI TTS | Normalize loudness before avatar generation. |
| Avatar face creation | Midjourney , Leonardo AI , Adobe Firefly | ComfyUI , Fooocus , AUTOMATIC1111 | Generate front-facing, clean-light portrait for best lip-sync results. |
| Avatar | HeyGen , Synthesia , D-ID , Tavus | LivePortrait , SadTalker , ComfyUI workflows | Use clean source portrait and neutral framing. |
| Edit | Descript , VEED , CapCut | DaVinci Resolve, local subtitle tools | Trim dead air and add scene transitions. |
Related pages: virtual avatar services · HeyGen alternatives · ComfyUI alternatives