
Mistral Small 4 alternatives
Open hybrid Mistral model that combines instruct, reasoning, coding, OCR, and transcription in one 256K-context family.
This Mistral Small 4 alternatives guide compares pricing, strengths, tradeoffs, and related options.
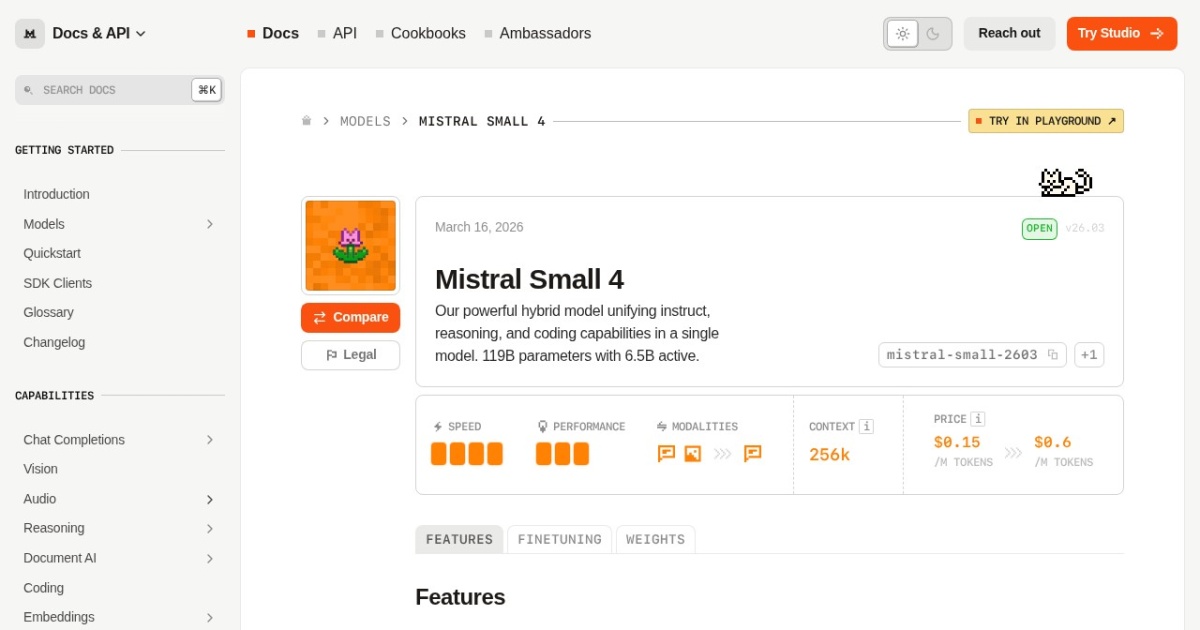
Mistral Small 4 is one of the strongest recent additions for builders who want a single open model that can cover general chat, coding, OCR-heavy document work, and transcription without jumping between several checkpoints. It is more interesting than older small local families because Mistral positions it as one practical open model for both software and document workflows.
Official site: https://docs.mistral.ai/models/mistral-small-4-0-26-03
Company YouTube: No official company YouTube channel found during official-page review.
At a glance
| Pricing model | Free |
|---|---|
| Page type | Model family |
| Model source | Own models |
| API cost | Mistral API lists Mistral Small 4 at $0.15 input / $0.60 output per 1M tokens. |
| Subscription cost | No mandatory subscription for open-weight access; hosted API is pay-as-you-go. |
| Model last update | 2026-03-16 (Mistral Small 4 docs release page). |
| Model weight counts | 119B total / 6.5B active |
| Model versions | Ministral 3 generation, Mistral Small 4 |
| Related model | Ministral 3 8B · Mistral Small 4 vs Ministral 3 8B |
| Key difference | Mistral Small 4 is the newer, much larger hybrid family with stronger coding, OCR, and multimodal capability; Ministral 3 8B stays the lighter long-context local option. |
| Best for | Multimodal local assistant workflows, Multimodal document understanding, Builders experimenting with vision-language tasks |
| Categories | For Solopreneurs , For Small Business , Free AI Tools , Developers , Local LLMs , Vision LLMs |
Model version timeline
Top alternatives
- Qwen3.6-35B-A3B : First open-weight Qwen3.6 model: a 35B total / 3B active multimodal MoE focused on agentic coding and practical local use.
- Qwen3.5 : Native multimodal Qwen family with sparse MoE scaling, strong agent behavior, and a flagship 397B total / 17B active open model.
- Gemma 4 : Newest Gemma family with Apache-2.0 licensing, multimodal input, 256K context, and sparse on-device variants.
- Qwen2.5 VL : Multimodal Qwen model family for local vision-language workflows.
- Llama 4 : Open-weight multimodal family with massive context, but significant policy and license constraints.
- InternVL 3.5 : Apache-2.0 multimodal family with many size options and a strong focus on reasoning, OCR, and agent-style visual tasks.
Notes
Mistral Small 4 is one of the most useful recent additions if you want one open model family that can cover chat, code, OCR, and document-heavy workflows.
Comparison table
| Tool | Pricing | Page type | Model source | API cost | Subscription cost | Pros | Cons |
|---|---|---|---|---|---|---|---|
| Mistral Small 4 | Free | Model family | Own models | Mistral API lists Mistral Small 4 at $0.15 input / $0.60 output per 1M tokens. | No mandatory subscription for open-weight access; hosted API is pay-as-you-go. | One family covers reasoning, coding, OCR, and transcription; 256K context is practical for large document and repo workflows | Still much heavier than 7B to 14B local models; Fresh releases can have uneven runtime support at first |
| Qwen3.6-35B-A3B | Free | Model family | Own models | No required vendor API cost for local/self-hosted use. | No mandatory subscription for base model access. | Much more practical than waiting for very large Qwen3.6 weights; Strong agentic coding uplift over the previous 35B-A3B branch | Still needs meaningful hardware compared with 8B-class local models; Hosted Qwen3.6-Plus remains the stronger top-end option if you can accept API dependence |
| Qwen3.5 | Free | Model family | Own models | No required vendor API cost for local/self-hosted use; hosted Qwen3.5-Plus access is usage-based in Model Studio. | No mandatory subscription for open-weight access. | Native multimodal design is stronger than many stitched vision-plus-text stacks; Sparse MoE design keeps active parameters much lower than total scale | The flagship open model is still far heavier than commodity-laptop local models; Newer runtime support may lag behind more established Qwen branches |
| Gemma 4 | Free | Model family | Own models | No required vendor API cost for local/self-hosted use. | No mandatory subscription for base model access. | Apache-2.0 licensing is simpler for commercial use than earlier Gemma branches; 256K context is strong for larger document and app workflows | 31B still needs serious local hardware compared with smaller VLM options; Fresh releases can have uneven runtime support at first |
| Qwen2.5 VL | Free | Model family | Own models | No required vendor API cost for local/self-hosted use. | No mandatory subscription for base model access. | Strong local multimodal capability set; Useful for document and visual analysis workflows | Heavier runtime needs than text-only models; Requires careful context and memory tuning |
| Llama 4 | Free | Model family | Own models | No required vendor API cost for local/self-hosted use. | No mandatory subscription for base model access. | Very large context windows for repository- and corpus-level tasks; Multimodal support for text and image understanding | License includes attribution and derivative naming obligations; Additional licensing conditions can trigger at very large scale |
| InternVL 3.5 | Free | Model family | Own models | No required vendor API cost for local/self-hosted use. | No mandatory subscription for base model access. | Broad model-size ladder for different hardware budgets; Strong multimodal reasoning and OCR direction | Best checkpoints are heavier than small local VLMs; Setup and inference tuning can be demanding |
Internal links
Related best pages
- Best Free LLMs for Solopreneurs
- Best Free AI Tools for Solopreneurs
- Best AI Automation Tools
- Best AI Email Marketing Tools